EIGRP
RIP, IGRP and EIGRP are different routing protocols. RIP stands for Routing Information Protocol; IGRP stands for Interior Gateway Routing Protocol; and EIGRP stands for Enhanced IGRP.
The main difference being RIP and IGRP are distance vector protocols; EIGRP is more of link state protocol. Then there is a difference in their operations, times (like updates, refreshes, etc.), how they keep track of routing tables, etc. I talk more about routing protocol’s different routing tables in this expert response.
You can find a lot of information off the Internet for these protocols. I would suggest you to check it out on cisco.com, and let me know if you have any specific queries on these protocols.
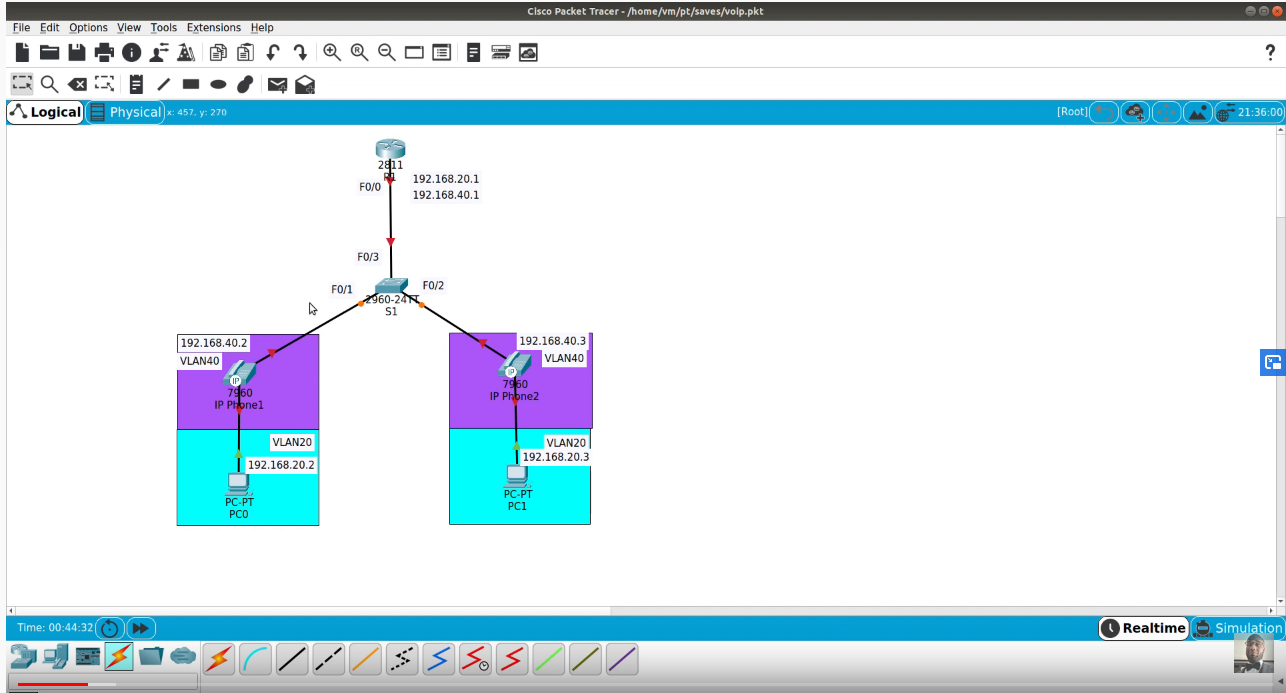
EIGRP offers fast convergence time and can scale to thousands of routers, spanning multiple autonomous systems. These attributes, along with Cisco’s dominance in the router market, have made EIGRP the de facto standard in large enterprise networks.
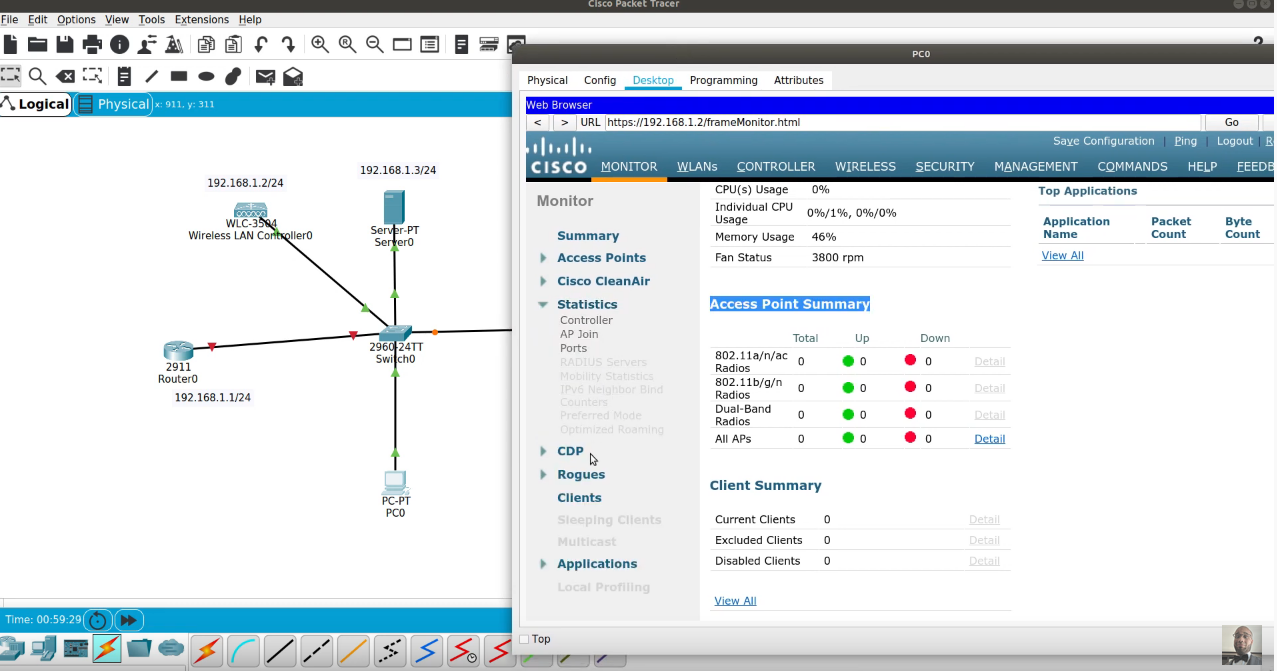
However, one particularly frustrating troubleshooting issue that EIGRP network engineers confront is known as a “stuck in active” (SIA) condition, where an EIGRP router fails to receive a reply to a routing-path query from one or more of its “neighbor” routers within an allotted time (typically three minutes, depending on the version of Cisco’s IOS in use). An SIA condition can cause EIGRP routers to drop neighbor adjacencies, negatively impacting service. Worse, if the dropped adjacency causes other SIAs, the problem can cascade throughout the network, affecting large numbers of users and causing major network outages.
More
To stave off a broad network reconvergence — or, at minimum, a reset adjacency leading to costly downtime — network administrators must locate the non-responding router before the active timer has expired. This tedious manual process involves starting at the router where the SIA most recently occurred, proceeding to the nearest neighbor router, and following the problem, router by router, back to its source. However, this effort frequently comes too late because, once the timer has expired and adjacencies are reset, it becomes virtually impossible to identify the router responsible for the original SIA condition; the network’s forensic “audit trail” has been erased. A senior network architect at a major pharmaceutical company likened the problem to “tracing footprints in the sand.” In most cases, an administrator cannot possibly notice an SIA event and react in time to find the source of the problem before the trail vanishes, with one likely result being a future recurrence of the problem. What’s more, in a large network, an SIA condition that causes downtime can have serious bottom-line consequences.
Whether or not the SIA condition is caught and remedied before adjacencies are reset, it is critically important to discover why the router failed to respond to queries and why the original route(s) went active in the first place. Common SIA triggers are flapping links, overloaded routers, and failure to configure route summarization. Routing configuration errors are especially problematic in large networks, where they can rapidly proliferate conditions that precipitate further SIA events.
IP Routing
In his book IP Routing (O’Reilly, 2002), Ravi Malhotra says, “the best preparation for troubleshooting [an EIGRP] network is to be familiar with the network and its state during normal (trouble-free) conditions.” He recommends that network engineers possess detailed knowledge of routing tables, summarization points and routing timers, plus extensive “what-if” scenario plans.
A new technology called route analytics for the first time gives EIGRP network administrators just this sort of knowledge. Route analytics solutions work by listening passively to all routing exchanges on the network and delivering a “router’s eye view” of Layer 3 activity — a complete and accurate network-wide topology map showing all EIGRP routes and events, both real-time and historical. A complete prefix advertisement history is maintained for the network, providing an audit trail that includes prefix type, AS of origin, metrics and more. These events are then resolved into the link-state change events that caused the EIGRP updates. Network engineers now can proactively monitor for faulty routing behavior caused by configuration errors or other problems. They can, for example, verify that all remote access routers are configured with route summarization to prevent rapidly changing route advertisements from precipitating SIA conditions. Misconfigured routing redundancy can be caught before it causes routers to go active on important routes. And any detected active route is automatically watched; if it doesn’t return to passive state soon, possible active/SIA query paths are probed to determine whether an SIA condition exists and, if so, where it originated.